Implement a task orchestrator (2)
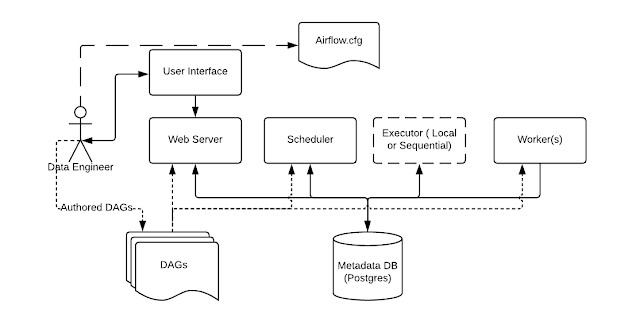
This follows a previous post Implement a task orchestrator (1) . As second part of the task orchestrator, we will implement: Scheduler Scheduler is a standalone application that continuously checks existing pipelines and schedules jobs. Before we create a scheduler, we first want to get all the existing pipelines and parse them into a format that can be handled by the scheduler. First, we create a parse module that import all modules in a file and save pipelines. import importlib , sys , time from model.Pipeline import Pipeline def parse (filepath): mod_name = f "{filepath}_{time.time()}" loader = importlib . machinery . SourceFileLoader(mod_name, filepath) spec = importlib . util . spec_from_loader(mod_name, loader) module = importlib . util . module_from_spec(spec) sys . modules[spec . name] = module loader . exec_module(module) pipelines = [] for attr in module . __dict__ . values(): if isinstance (a...